Duplicate Content. SEO-experts hebben er al veel over gezegd en geschreven. Voor de ene is het de doodsteek voor je positie in Google, voor de andere is er geen vuiltje aan de lucht. Hoe zit dat nu precies?
Inhoudstafel
Wat is duplicate content?
Duplicate content kan je vrij letterlijk nemen. Het ontstaat wanneer er meerdere pagina’s zijn die exact dezelfde inhoud hebben. Dat kunnen interne pagina’s zijn op je eigen website, maar het kan ook zijn dat je content exact overneemt van een andere website of vice versa.
Word je afgestraft voor duplicate content?
Er heerst een mythe dat je door Google hard wordt afgestraft van zodra je duplicate content op je website hebt. Natuurlijk is dat wat te kort door de bocht. Het gebeurt namelijk heel vaak dat mensen meerdere pagina’s hebben met dezelfde inhoud, vaak zonder dat ze het weten.
Dit kan bijvoorbeeld gebeuren wanneer je gebruikmaakt van:
- URL-parameters (zoals mijnwebsite.be/krabpaal?kleur=zwart)
- Meerdere variaties van je domeinnaam (zoals www.mijnwebsite.be en mijnwebsite.be). In dat geval is de URL-anders, terwijl de inhoud van de pagina wel gelijk blijft.
Dat soort duplicate content ontstaat vaak door technische foutjes (die ook worden gecheckt in een technische SEO audit) en hiervoor word je niet rechtstreeks afgestraft, maar het kan volgens Google wel een impact hebben op je prestaties (zie verder).
Dat je niet zomaar klakkeloos teksten mag overnemen van andere bronnen, heb je wellicht geleerd op school. Dat geldt hier ook nog steeds. Wanneer je zomaar content kopieert van andere sites, zonder er zelf nuttige toevoegingen aan te doen, straft Google je hier wel voor af. Google maakt dus een duidelijk onderscheid tussen “normale” duplicate content, en duplicate content met slechte opzet.
De algemene regel voor SEO blijft hier ook gelden: je website moet ‘value’ brengen. Wanneer jouw website geen originele inhoud bevat, heeft Google geen enkele reden om jouw website hoger in de zoekresultaten te plaatsen. Een website wiens business model berust op het overnemen van content van andere sites, wordt door Google gezien als ‘kwaadwillend’. Dat soort prestaties worden altijd afgestraft.
Wat zijn de nadelen van duplicate content op je website?
Alhoewel je bij normaal gebruik dus geen straf zal krijgen van Google omwille van duplicate content op je website, zijn er toch enkele reden waarom je het liever wil vermijden.
Minder controle over de zoekresultaten
Bij meerdere pagina’s met dezelfde inhoud, zal Google zelf kiezen welke URL naar boven komt in de zoekresultaten. Mogelijks is dat niet de pagina die je wil laten ranken. Het gebruik van een canonical-tag signaleert aan Google welke pagina de voorkeur heeft voor weergave in de zoekresultaten.
Meer crawlbudget nodig
Hoe meer pagina’s op je website, hoe meer werk Google heeft om je website te crawlen. Zoals beschreven in ons artikel over crawlbudget is dit echter pas een probleem bij websites met een aanzienlijke hoeveelheid pagina’s (zoals nieuwssites of grote webshops).
Geen centralisatie van backlinks
Backlinks zijn een van de krachtigste middelen om een pagina beter te laten scoren in de zoekresultaten. Wanneer je voor een en dezelfde pagina 20 URL’s hebt, zijn de backlinks verspreid over deze verschillende pagina’s. Het is verstandiger om alles te centraliseren op één pagina, zodat alle backlinks naar deze pagina kunnen leiden en deze pagina steeds sterker wordt.
Hoe gaat Google om met duplicate content?
Alhoewel meerdere pagina’s met dezelfde inhoud dus niet meteen een probleem hoeven te zijn, kan het wel een impact hebben op de prestaties in de zoekmachines. Google wil namelijk dat alle zoekresultaten uniek zijn, in plaats van meerdere zoekresultaten te tonen die allemaal naar dezelfde pagina leiden.
Google zal alle URL’s die naar dezelfde pagina leiden, bundelen in een ‘cluster‘. Vervolgens gaat Google zelf kiezen wat de meest geschikte URL is om te tonen in de zoekresultaten. Alle populariteit wordt vervolgens toegekend aan die ene specifieke URL.
Hoe vermijd je duplicate content?
Wanneer je meerdere pagina’s hebt met dezelfde inhoud, zijn er twee manieren om dit probleem aan te pakken:
- Canonical tags
- Redirects
Canonical tags
Via een canonical tag kan je aan Google signaleren welke pagina de ‘originele’ inhoud bevat. Een canonical URL kan je makkelijk instellen via SEO-tools zoals Yoast en Rank Math. Elke pagina zou standaard een self-referencing canonical tag moeten hebben die naar zichzelf verwijst.
Redirects
De meest robuuste manier is om redirects op te zetten met statuscode 301 (‘permanently moved’). Iedereen die dan een bepaalde URL bezoekt op je pagina, wordt automatisch doorgestuurd naar een andere URL. Aangezien ook Google wordt doorgestuurd naar deze nieuwe URL, zullen alle ‘oude’ URLs verdwijnen uit Google zodat enkel de eindbestemming blijft bestaan.
Redirects kan je aanmaken op serverniveau (idealiter), maar kan ook gebeuren via een WordPress plugin. Veel SEO-plugins komen standaard met een redirections-module, zoals Rank Math (al moet je die module eerst nog even activeren in de plugin instellingen).
Vervolgens kan je redirects aanmaken:
Hoe spoor je duplicate content issues op?
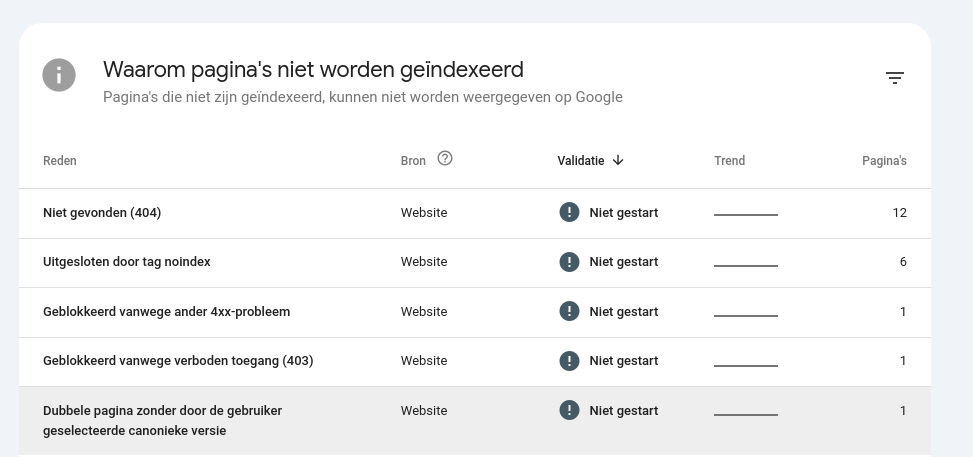
Wanneer Google bepaalde pagina’s op je website niet indexeert wegens duplicate content, kan je dit terugvinden in je Google Search Console (nog een reden waarom het opzetten van Google Search Console essentieel is voor je SEO-campagne).
Onder ‘Indexeren’ vind je het menu-item ‘Pagina’s’. Door dit te openen, kan je in het overzicht “Waarom pagina’s niet worden geïndexeerd” ontdekken of er duplicate content issues zijn.
In het voorbeeld hieronder zie je ook specifiek dat Google signaleert dat er een pagina is met duplicate content, waar er geen canonieke versie (canonical tag) voor is. Daarom besluit Google om deze pagina weg te laten uit de zoekresultaten. Door op deze melding te klikken, zie je specifiek om welke pagina’s het gaat.